
MCP Context Poisoning: The Agentic AI Attack Vector Enterprises Can’t Ignore



Anthropic just gave the industry a live-fire demo.
In five days, the most well-funded AI safety lab exposed its own playbook - first through a CMS misconfiguration, then through a source code leak that spread across GitHub before anyone could contain it. This wasn’t just sloppy ops. It showed how fast AI systems break when you move faster than your controls - and it landed right as Anthropic navigates political scrutiny over how it governs powerful models.
The real issue isn’t the leak. It’s what the leak proved.
MCP - the Model Context Protocol - now powers enterprise AI. It drives tens of millions of SDK downloads every month. The Linux Foundation governs it. Every major vendor builds on it.
And it ships with a structural blind spot.
MCP context poisoning.
What Anthropic Actually Exposed
On March 26, a misconfigured CMS exposed thousands of internal assets, including a draft announcing a next-gen model Anthropic itself flagged as risky.
On March 31, Anthropic shipped unobfuscated source code inside its Claude Code package. That code showed exactly how its agent runtime works.
Researchers didn’t fixate on IP. They focused on architecture.
They found something more important: Claude Code treats MCP tool results as trusted, persistent context.
No compression. No decay. No guardrails.
That decision created a durable attack surface inside the agent itself.
The Attack Path: Poison the Memory, Not the Prompt
Most people still think in terms of prompt injection. That model already feels dated.
Context poisoning plays a different game:
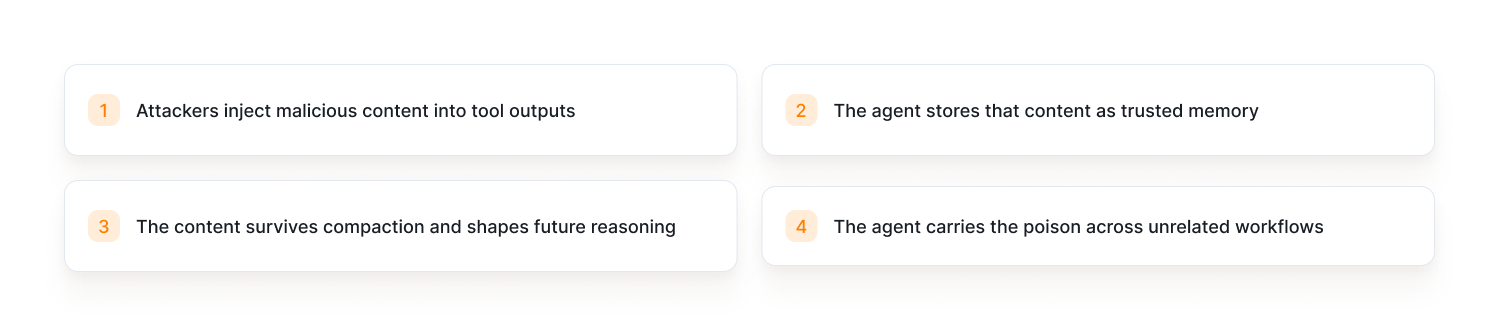
You don’t override instructions.
You rewrite memory.
Worse, MCP elevates tool metadata to system-level context. A poisoned tool doesn’t even need to run. Its description alone can steer behavior.
That’s not edge-case risk. That’s default behavior.
The Data Already Looks Bad
The ecosystem didn’t wait for Anthropic to break.
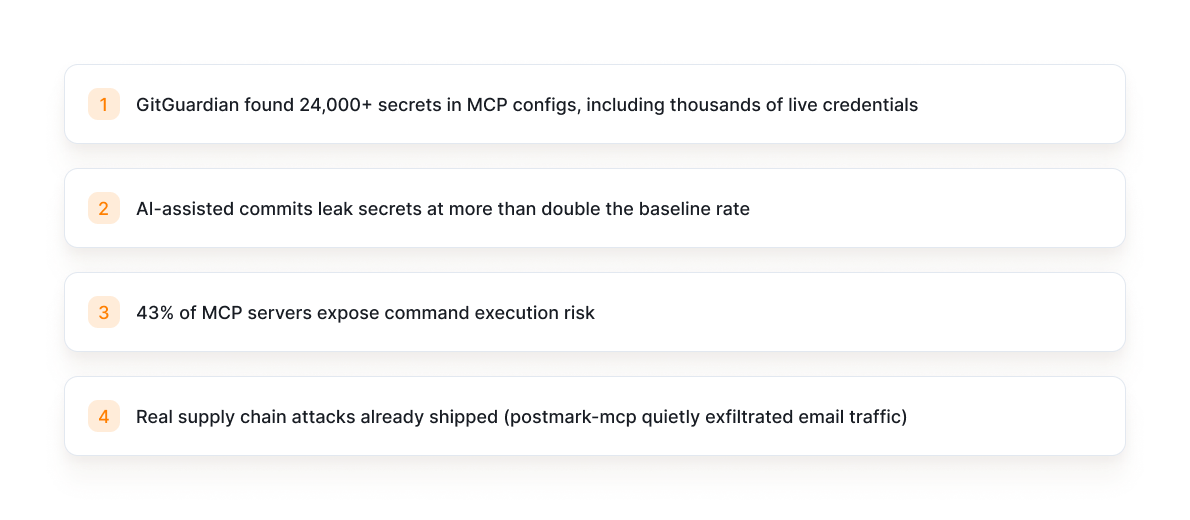
Benchmarks like MCPTox show high success rates for tool poisoning across major agents.
OWASP already ranked it as a top agentic risk for 2026.
We don’t need hypotheticals. We have telemetry.
RSAC Got the Perimeter Right - and Missed the Core
At RSAC, vendors moved fast:

That work matters. It closes obvious holes.
But it ignores the real problem: what happens after the tool call succeeds.
Identity verifies who made the call.
Network controls govern where it goes.
Neither inspects what actually flows through the system.
Context poisoning lives in that gap.
A fully authenticated, policy-compliant tool call can still deliver poisoned content that hijacks the agent.
That’s the layer enterprises still don’t defend.
Why Your Current Stack Won’t Catch This
Your controls stop at the perimeter.
They don’t:
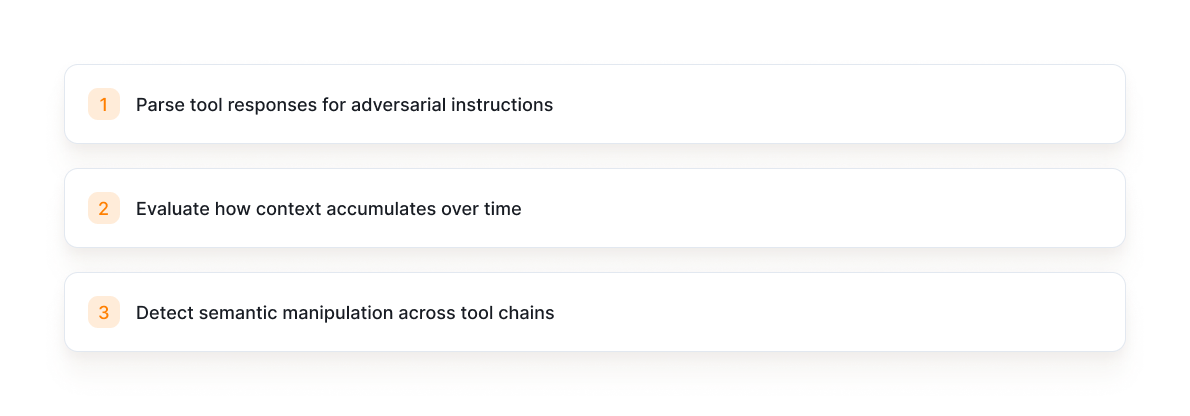
Attackers don’t need to break auth.
They just need to ride it.
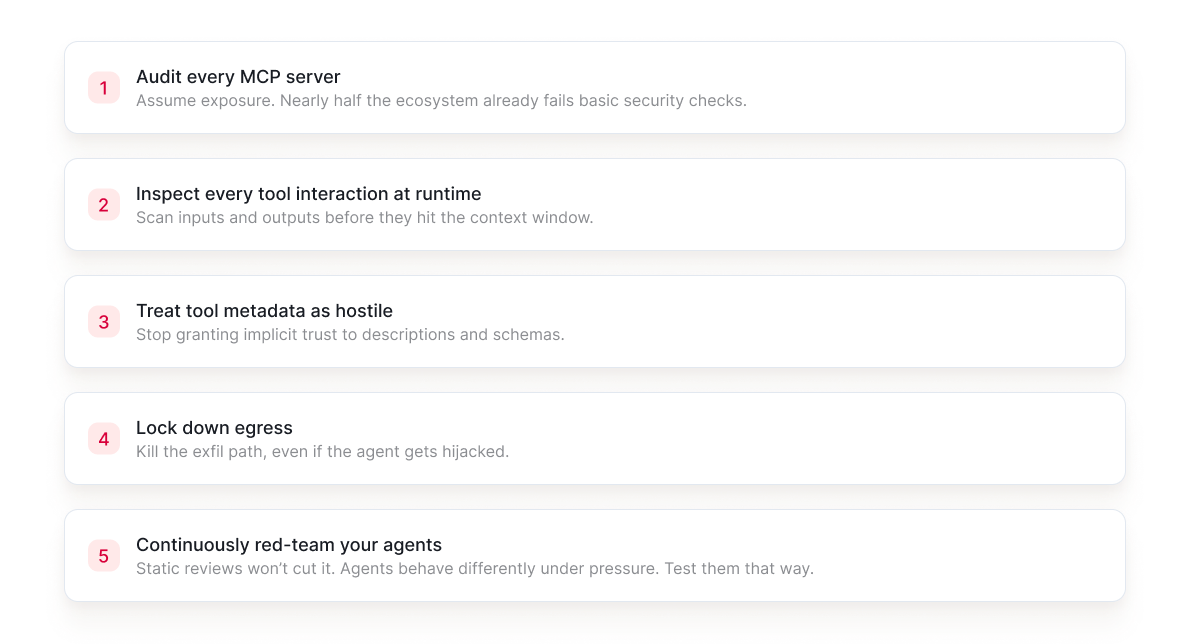
What to Do Now
Move fast, but don’t pretend your current controls cover this.
The Bottom Line
MCP isn’t going away. It already anchors enterprise AI.
But right now, enterprises scale adoption faster than they secure the protocol layer. Anthropic’s leaks - paired with the political pressure now surrounding how labs ship and govern these systems - make one thing clear: even the leaders don’t have this fully under control.
Context poisoning turns the agent’s greatest strength - memory - into its biggest liability.
The winners in the agentic era won’t just secure models or lock down access.
They will inspect, challenge, and control the content flowing through every tool interaction.
Everything else leaves you exposed.
Frequently Asked Questions
MCP context poisoning rewrites agent memory through tool metadata instead of overriding instructions like prompt injection does. Poisoned tool descriptions alone can steer agent behavior without the tool ever running, creating a durable attack surface inside the agent itself.
- Targets persistent context stored by MCP tools, not input prompts.
- Exploits trusted tool metadata treated as system-level context.
- Succeeds even when authentication and network controls pass.
Enterprises must inspect what flows through authenticated tool calls, not just verify who made them. Real-time policy-based guardrails at the runtime layer catch poisoned content after successful tool execution, closing the gap current perimeter controls miss.
- Deploy runtime agent guardrails to block malicious context injection.
- Scan MCP servers for prompt injection, code injection, and misconfiguration.
- Enforce centralized security policies across all agent deployments.
MCP context poisoning is default behavior in major agent systems, not an edge case. Benchmarks like MCPTox show high success rates across agents, OWASP ranked it as a top agentic risk for 2026, and attackers don't need to break authentication—they just ride it.
- Affects tens of millions of MCP SDK downloads monthly across enterprise AI.
- Works against fully authenticated, policy-compliant tool calls.
- Requires no IP theft or system compromise to succeed.
Enkrypt AI provides end-to-end MCP governance with dedicated scanning, policy enforcement, and runtime protection specifically designed to stop context poisoning. The platform covers 300+ red-teaming risk categories and reduces manual compliance effort by up to 90%.
- MCP Scanner assesses servers for context poisoning and misconfiguration.
- MCP Gateway enforces policies at runtime with ultra-low latency protection.
- Agent guardrails block poisoned content after tool execution succeeds.
Enkrypt AI detects poisoned context before it hijacks your agents. Book a demo to see how it catches MCP attacks your current stack misses, or start a free trial today.


.jpg)


